Diese Seite wird nur in Englisch angeboten. Sorry.
This page/data was last updated 2015-11-23
The statistics are stored in form of simple
ASCII list, tables ands matrices
that may be downloaded for easy further processing.
The coding is 7-bit ASCII to avoid the typical problems of different
codings such as Iso8859 or Unicode; characters that are not 7-bit ASCII
are coded in LaTeX; phonetic symbols are coded in extended German SAM-PA.
We provide the simple counts, the basic probability of a single entities,
condition probability that the entity occurs in certain contexts,
statistics of durations under varying conditions,
as well as the conditional probabilities for an certain entity occuring right
after another certain entity (bigram).
Schiel F (2010): BAStat: New statistical resources at the Bavarian Archive for Speech Signals . In: Proc. of LREC 2010, Valletta, Malta, paper 277.
Note that German SAM-PA deviates from the official German SAM-PA in that the glottal stop is labelled as /Q/ instead of /?/ since the question mark often leads to errors in UNIX based processing software. Further, the German SAM-PA contains un-lengthened tense vowels /e/, /i/, /o/, /y/, /2/ and /u/, the nazalised vowels /a~/, /E~/, /O~/ and /9~/, and no affricates (phonemes of affricates are labelled and segmented separately).
Para-linguistic segment markers often used in technical speech processing such as articulatory noise (cough, throat clear etc.), laughing or silence intervals are not considered. That is, we provide no priors for these events but bigram statistics to and from silence intervals and word boundaries (see section Phoneme Bigram Statistiscs below). The reason is that these para-linguistic events are marked quite differently and inconsistently accross different corpora.
All phone segments belonging to a filled pause (hesitation) are excluded from the analysis, because these phones behave in a different way than phones embedded in spoken words. (For instance they may be exceedingly long.)
Since there also exist triphthongs and additional diphthongs in German that all end in /6/ and it is not clear whether they should be treated as entities or not, we calculate two sets for the first order statistics (apriors): one with the basic phone list (47) and one with the additional 24 /6/-combinations (76).
Basic German Phone List (52)
German Phone List extended by /6/ combinations (76)
Since large corpora of manually segmented spontaneous German are not available, most of the following results are based on the automatic MAUS transcript.
Phone Monogram Statistics
Each list of first order statistics contains a four-lines
header with the name of the data set,
the number of words and the number of entities and a table header
followed by a 26-column
table. The TAB separated elements of the table are:
not considering the case of a word that consists only of one phone. Therefore these
three conditional probabilities do not sum up to 1.
e.g. (only first 8 columns are shown):
Database TOTAL
Words 557561
total 2124420
Phon Count P(Phon) P(WI|Phon) P(WF|Phon) P(WM|Phon) Mean(Phon) SD(Phon)
aI 47890 2.254262e-02 1.493005e-01 1.631238e-01 6.859261e-01 1.289775e-01 8.806708e-02
OY 4884 2.298980e-03 0.000000e+00 3.521704e-02 9.647830e-01 1.235842e-01 4.567128e-02
aU 19964 9.397388e-03 4.264676e-01 1.361451e-01 4.156482e-01 1.365879e-01 6.872048e-02
...
The probability in the third column is the estimate for
P(phone); consequently the third column sums up to 1.
Statistical duration values are given in secs. Since some phone segments
are exceedingly long because of very long hesitations or - possibly - caused
by errors in the automatic segmentation algorithm, segment durations above
2000msec are reduced to the average phone duration of 90msec,
before calculating the statistical values.
The conditional probability for
given the phone it being a single-phone word is 1 minus the
4th, 5th and 6th column.
Verbmobil 1
Basic German Phone Statistics
(Note that this statistic is based on the training set only; the test and
the development sets are not included and may therefore be used for
independent testing.)
German Phone Statistics extended by /6/ combinations
Basic German Phone Statistics
German Phone Statistics extended by /6/ combinations
The rows define the predecessor phone phon1 (indexed in the first
column), while
the columns define the successor phone phon2 (not indexed but in the same
order as the rows), one single element contains the linear
conditional probability P(col=phon2|row=phon1). Consequently, the elements
of each row sum up to 1 (because per definitionem after each given phone
must follow another, and hence the probabilities over all possible successors sum
up to 1).
For technical reasons the last line indexed by phon1 = !EXIT also
contains equally distributed
probabilities summing up to 1 although !EXIT has no successor.
If other entries than the first column
are zero, this means that the bigram combination was not
seen in the input corpus/corpora. You may apply standard discounting techniques to
obtain non-zero probabilities for these cases.
Identical values following each other are indicated by an optional counter added
to the probability, e.g. 8.968610e-03*2 = 8.968610e-03 8.968610e-03
Each bigram matrix file contains a three-line, two-column header listing
the name of the database, the total number of words and the total number
of phonemes followed by the matrix as described above.
Phoneme Bigram Statistics
Second order statistics or conditional probabilities P(phon2|phon1) or
diphone statistics or bigram (all synonyms for the same thing) are given in form
of a matrix containing all un-smoothed conditional probabilities P(phon2|phon1)
where phon1 is the predecessor and phon2 is the successor.
If n = number of entities, then the matrix is (n+3) cols x (n+2) rows
since the first column contains an index to the entities and the
!ENTER and !EXIT pseudo entities are added to the data to
model entry and exit bigram probabilities of utterances.
(Note that the latter only make sense if the corpus is segmented into
utterances! This feature is marked for each corpus individually below!)
Since the 2nd colum contains the probabilities for phon2 = !ENTER but
!ENTER has no predecessor, all values in this column are set to zero, to
avoid a distortion of the remaining values in the rows.
Verbmobil 1
Bigram Matrix based on basic phone set
(Note that this statistic is based on the training set only; the test and
the development sets are not included and may therefore be used for
independent testing.)
Bigram Matrix extended by /6/-combinations
Bigram Matrix based on basic phone set
(Excel version,
CSV version)
Bigram Matrix extended by /6/-combinations
Classical questions often asked are:
'What is the probability for phone /x/ to occur
with the left-context phone /y/?'
or:
'What is the probability for phone /x/ to occur
with right-context phone /z/?'
or:
'What is the probability for phone /x/ to occur
with left-context phone /y/ and right-context phone /z/?'
These can be answered by calculating the probability of the cooccurrence
of an ordered pair of phones (y,x) or (x,z) or an ordered triplet (y,x,z)
by combining the first and second order statistics and ignoring higher order
statistics.
P(yx) = P(col=x|row=y) * P(y)
or:
P(xz) = P(col=z|row=x) * P(x)
or:
P(yxz) = P(col=z|row=x) * P(col=x|row=y) * P(y)
The latter is merely an estimate since the statistical dependencies
between the left and the right context (between y and z) are being
ignored here.
(Please note that here P(yx) is not equal to P(xy) since the cooccurrence
is ordered! The well-known Bayes formula P(A|B) * P(B) = P(B|A) * P(A)
is still valid for this case but you have to use a different matrix for the
lookup of P(B|A) since the meaning of P(A|B) is not 'the probability of
A while B is given' but rather 'the probability of A occurring
after B given that B occurs' and P(B|A) would then be 'the probability
of B occurring before A given that A occurs', which is not given in our
bigram matrix.)
Examples:
What is the probability of /n/ with left-context /E/ in any word position
(e.g. 'Mensch', 'entzückt', 'mondän}'):
Waht is the probability of a word-initial /p/ with right-context /r/ (e.g. 'pr�fen'):
The estimate for the probability of high-frequent word-final syllable /g@n/ (e.g. 'legen'):
The estimate for the probability of high-frequent word-internal syllable /g@n/ (e.g. 'legendär'):
The estimate for the probability of low-frequent word-final syllable /vOYs/ (e.g. 'Konvois'):
Caution 1:
(This is actually confirmed in this case by looking up the syllable monogram statistics below, which predicts
a zero probability for a word-internal syllable /g@n/ and a non-zero probability for the word-final position.)
Caution 2:
Statistics of Phone Strings / Phones in Different Contexts
First re-formulate
the question into the form 'y is followed by x' or 'x is followed by z'
or 'y is followed by x followed by z'
respectively and then apply the following formulae:
Following the same scheme the probability of larger phone strings
(for instance syllables) may be estimated.
P(col=n|row=E) * P(E) = 9.874496e-02 * 2.415072e-02 = 0.00238476
P(col=r|row=p) * P(p) * P(word-initial|p) = 2.249895e-01 * 1.968239e-02 * 2.466251e-01 = 0.00109213
P(col=n|row=@) * P(col=@|row=g) * P(g) * P(word-final|n) =
2.708625e-02 * 3.030752e-01 * 1.853434e-02 * 5.013115e-01 = 7.6275e-5
P(col=n|row=@) * P(col=@|row=g) * P(g) * (1 - P(word-initial|n) - P(word-final|n)) * (1 - P(word-initial|g) - P(word-final|g)) =
2.542894e-02 * 3.029079e-01 * 1.880843e-02 * (1 - 1.224357e-01 - 4.933440e-01 ) * (1 - 6.239958e-01 - 1.148735e-02) = 2.026100e-05
P(col=OY|row=v) * P(col=s|row=OY) * P(v) * P(word-final|s) = 9.688200e-05 * 1.885138e-02 * 2.265478e-03 * 4.365535e-01 = 1.806273e-09
Since these are merely estimates caution should be taken to take these for absolute values. For instance it is
probably not correct to state: "The probability for the word final syllable /g@n/ is 7.6275e-5!" but we can
say with some confidence that
"The probability for the syllable /g@n/ is higher in word-final than in word-internal position."
Since our statistic is based on finite data sets and number of observed items differs considerably
between phone, syllable and word statistics, it is not possible to combine estimates from different
statistic types (phones, syllables, words) into one estimate!
Syllables
Syllable statistics are based on an automatic syllabification of the phonetic
transcripts derived from MAUS. The syllabification
was written by Uwe Reichel; it is rule-based and basically identifies the nuclei within
each word and then searches for sonority minima between nuclei and applies some other rules
to set the syllable boundaries. Word boundaries act as anchors that is syllables are not allowed
to spread to the previous or next word. This results in 'syllables' like /s/
(a reduced 'ist') or /n/ (a reduced 'ein' or 'einen').
Since the number of empiric syllable types in our database is quite
high, we do not provide the statistics of the individual corpora but
rather a total statistics covering all corpora described above.
This includes also the test and development test sets of the Verbmobil corpora;
therefore the number of words in the following statistics is slightly
larger than the ones listed in the phone statistics above.
In case you need the syllable statistics for the Verbmobil training sets only, please contact me and I can provide you with the data.
Raw Segmental Data
The resulting syllable segments were collected into
a table with 8 columns:
SYLLABLE DURATION WORD CANONICAL SYLPOS REFERENCE WORDNR WORDDURATION
where REFERENCE is a file identifier of our internal database
that allows us to find the corresponding recording and
WORDDURATION is the duration of the word from which this syllable was taken
given in secs (this comes handy, if you want to normalize the syllable duration
against different speaking rates).
WORDNR points to the word within this recording from which
this syllable was taken (starting with '0').
SYLPOS is of the form (Pos,Max), e.g. (2,5) is the second
syllable in a 5 syllable word.
CANONICAL is the citation form pronunciation of the word
coded in German SAM-PA (with
/Q/ instead of /?/ for the glottal stop).
WORD is the orthographic form of the word token as described in
the word section of this page.
DURATION is the duration of the syllable given in secs.
SYLLABLE contains the German SAM-PA coding of the syllable but also
a leading ' if the syllable was marked as lexically accented (derived from
CANONICAL) and a trailing '+' if the syllable is part of a function word (a
non-content word, derived from the manual tagging).
Both latter markers (',+) are not 100% correct, since
Since syllable analysis can be tricky, we provide these raw data as well as the following statistics derived from it. Please feel free to use these data for your own studies.
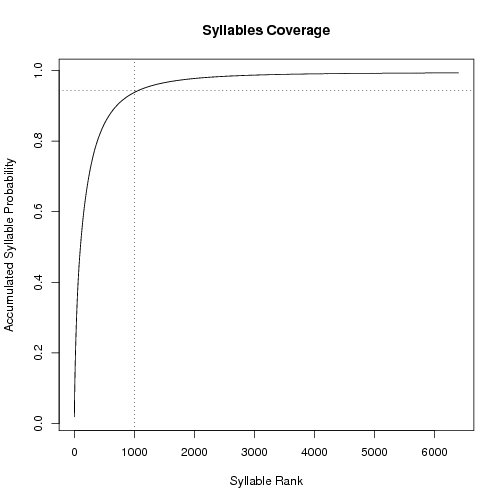
RANK SYLLABLE COUNT PROBABILITY ACCUMULATED-PROBABILITY
Please note that here lexical accentuation and word class (content vs. function) is not considered. That is, the probability given here includes all taggings for a given syllable. For a more detailed analysis see the monogram and duration statistics in the next section.
As can be seen from this table the first 1000 top ranked syllables cover over 94,37% of the analysed corpora speech. Also, it is interesting to note that the German syllable /ja:/ (the German affirmative) is the most frequent syllable in conversational speech. (Followed by /IC/ (1st person singular pronoun); so it seems we mostly talk affirmative about ourselves ;-)
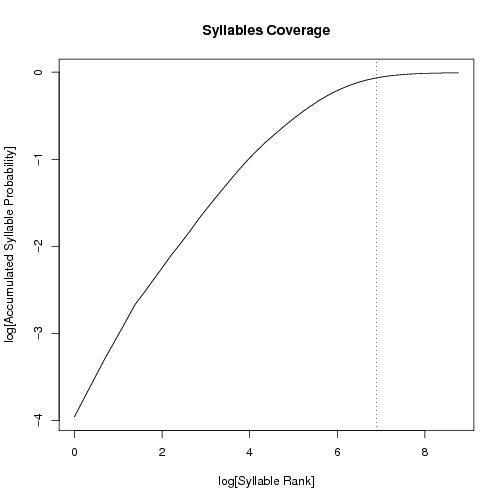
The following figures plot the accumulated probability (the mass) across the ranking of syllables.
The number of syllable types in this table is higher then the
number of entries in the syllable ranking table, because here an accented syllable and
an unaccented syllable are two different types.
Some of the counts do not add up; this is caused by inconsistent
tagging of function words: some word types are tagged as content
and as function word.
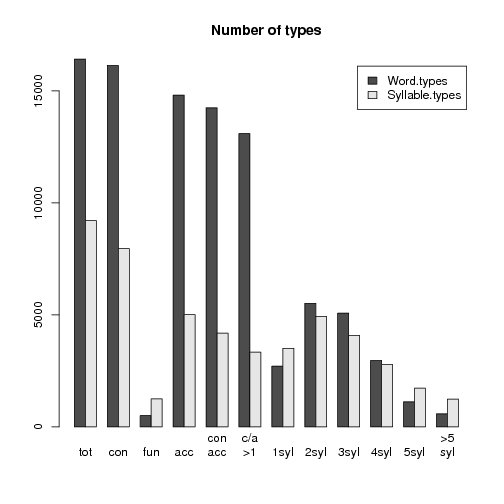
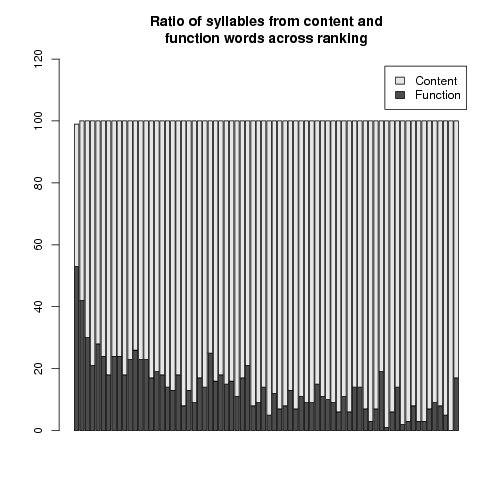
For instance the following figure shows the number of distinctive word and syllable types found in the data sorted by different filters (left side or top) and the ratio of content (grey) vs. function words (black) accross the syllable ranks (right side or bottom):
where:
tot = total number of types
con = from content words only
fun = from function words only
acc = marked as carrying a lexical accent
con acc = marked as carrying a lexical accent in content words
c/a >1 = marked as carrying a lexical accent in content words with more than one syllable
1syl = one-syllable words
2syl = two-syllable words
3syl = three-syllable words
4syl = four-syllable words
5syl = five-syllable words
>5syl = more than five-syllable words
Although the number of syllable types found in function words is very small compared to content words
(left figure, bars 'con' and 'fun'), the ratio between syllable tokens
taken from content and function words
(right or bottom figure) shows that function word syllables are not only found in the top ranking (in the
syllables with the highest probabilities) and must be very repetitive (since
the token ratios are much higher than the type ratios).
Syllable Monogram and Duration Statistics TOTAL
The following figures show some example data derived from this table.
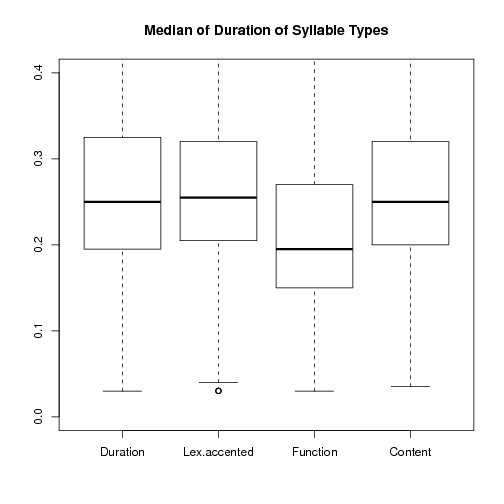
These boxplots (left or top) show the distribution of the medians of the duration of
each syllable type. That is, each syllable type is represented by one
data point in this distribution and the probability of the syllable type
is not considered here. Contrary to expectation the distribution of lexically
accented syllables in words with more than one syllable ('Lex.accented')
does not deviate from the distribution over all syllable types
('Duration'). However, as expected the distribution of syllables
derived from function words shows smaller durations than the syllables
derived from content words (which is only slightly elavated from the overall
distribution).
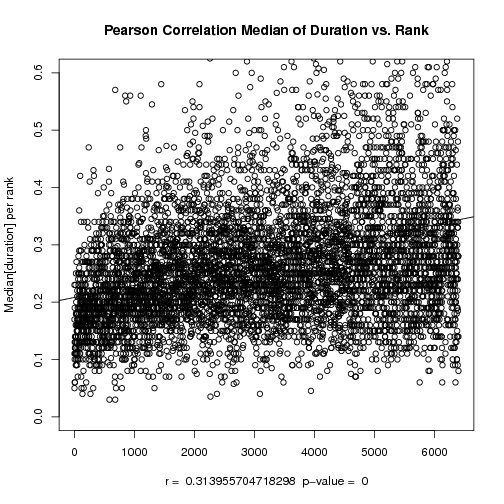
The Scatter plot (bottom or right) shows the medians per syllable type across
ranking order. As expected there is an inverse correlation between rank and
duration but the Pearson correlation is with r = 0.31 very weak.
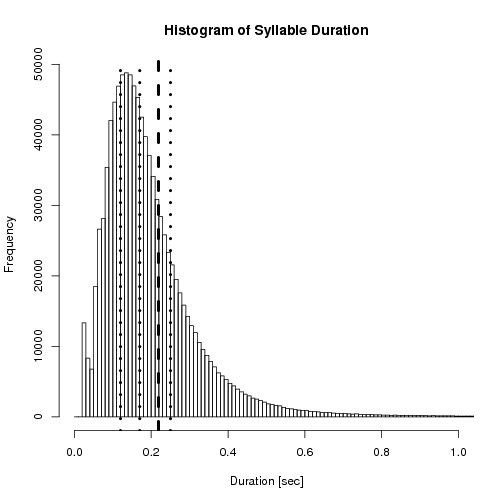
The (left or top) histogram shows the distribution of the syllable durations
after filtering syllables belonging to hesitations (often exeedingly long) and
syllables only containing the garbage sound (<usb>). The dashed line marks the
arithmetic mean (0.21sec) while the dotted lines mark the quarter-quantiles
25% (0.12sec), 50% (median, 0.17sec) and 75% (0.25sec).
See section Phone Bigram Statistics for details about the
file format.
Bigram Matrix based on raw syllable type list
The results are stored in a four-column table with a three
line header:
Database
The columns of the following table are:
Word Pronunciation Statistics TOTAL
The word label '<%>' denotes an unintelligible word;
likewise the phonetic label '<usb>' is the phonetic garbage symbol.
'$' denotes a spelling.
The following first and second order statistics are based on a
list of raw word types coded in 7-bit ASCII LaTeX
(if a token starts with an Umlaut,
the leading " is quoted with a backslash, e.g. '\"Arger'):
This list contains all transcribed items (including some meta tags; see below) that
can be found in the analysed corpora described in the Phoneme Statistics
sections.
See section Phoneme Bigram Statistics for details about the
file format.
Bigram Matrix based on raw word type list
The top 100 rank bin (left-most bar in right or bottom figure) shows that
more than 50% of the top 100 syllables belong to function words.
Syllable Monogram Statistics
In analogy to the phone monogram statistics presented in the Phone section
we produce a table of same order and length as the ranking list
above containing different conditional probabilities and
duration statistics that might be helpful.
The table starts with a four-lines
header with the name of the data set,
the number of syllable types and tokens and a table header
followed by a 50-column
table. The TAB separated elements of the table are:
Statistical duration values of empty data partitions are set to -1.
For instance a syllable that never occurs word final will have all 5
duration values assigned to word final syllables set to -1. The conditional
probability of being a syllable in a one-syllable word can be calculated by
1 - P(WI|Syl) - P(WF|Syl) - P(WM|Syl).
The histogram pretty much ends around a syllable length of
1.0 secs (after that only outliers caused either by excessive sound lengthening
or - more likely - caused by segmentation errors occur).
Hence, for the duration statistic
presented above we filter all syllables that have a duration of greater than
1.0secs (= 0.657% of all syllables).
Syllable Bigram Statistics
Based on the raw syllable tokens and the syllable ranking list of basic
syllable types (lexical accentuation and function word markers not
considered) we calculate
a simple un-smoothed bigram statistic from the syllable sequences
of the transcribed conversational speech corpora. Since the database is far to
narrow for a proper second order statistic we provide only the bigrams based on
a merger of all corpora as described in the Phone Statistics sections.
Words
Word statistics are based on the raw word tokens taken from the
respective corpus; no pre-processing is performed except that capitalized words
at sentence beginnings are normalized to the un-capitalized form as found in dictionaries.
We provide a statistics of pronunciation variants, the basic monogram statistics,
average word duration, canonical pronunciation and syllable count, as well as the bigram probabilities.
Word Pronunciation Statistics
Since the phone segmentation in BPF is linked to word labels
it is possible to count different pronunciations for the
same word token and estimate the conditional probability
P(P|W), given the orthographic word form W with which
probability will the pronunciation P (in SAM-PA) occur.
Since the relation between word tokens and word forms is only
about 120:1 we estimate only the total statistics from all
source corpora joined together.
Pronunciation types
Pronunciation tokens
ORTHOGRAPHY PRONUNCIATION(SAM-PA) COUNT P(P|W)
Please note that these raw word types are not necessary valid word forms. Since
the database is conversational speech the list may contain 'non-words'
such as word breaks, neologisms and dialectal variants.
The following 'meta tags' are also included in the basic word list,
since their statistics might be useful:
Consequently, the number of word tokens in this section is larger
than in the previous sections where only pure word tokens were
taken into account.
Proper names of persons, institutions or locations which consist of several words are
in some cases concatenated into one string without blanks, e.g. the movie title
'American Hero X' is listed as 'AmericanHeroX'.
Word Monogram Statistics
Based on the list of raw word types
the following statistics are derived from the transcribed conversational
speech corpora. The table consists of the usual three-lined header followed
by a 6-column table with the following entries per word type:
Word Monogram Statistics based on raw word type list
Note: the duration values of meta tags (!....) are not valid!
Word Bigram Statistics
Based on the same list of raw word tokens as in the Word Monogram section
a simple un-smoothed bigram statistic is calculated from the word sequences
of the transcribed conversational speech corpora. Since the database is far to
narrow for a proper second order statistic we provide only the bigrams based on
a merger of all corpora as described in the Phoneme Statistics sections.
| CELEX | BAStat | |
| Word tokens | 5002442 | 689966 |
| Word types | 84173 | 16426 |
| Syllable tokens | 9062607 | 1030588 |
| Syllable types | 7030 | 9210 |
Although the number of word and syllable tokens is about one
magnitude higher in CELEX than in BAStat, we find about the same
number of syllable types in both resources.
The ratio of words types against word tokens
is in CELEX (1.7%) lower than in BAStat (2.4%); this
is probably caused by the insufficiant number of word tokens in
BAStat: while the number of word types in CELEX is probably nearly
converged, in BAStat the number of word types will probably still
grow with increasing corpus size.
From the smaller amount of word types in BAStat we would
also expect a proportional smaller number of syllable types, but this
is not the case: the number of syllable types in BAStat exceeds the
number in CELEX. The reason is probably that the phonetic variation
of syllables produces more syllable forms than in the phonological
paradigma of CELEX, where each word token has always the same syllables.
The statistic of syllable types also differs considerably: in the following
we plot the first 20 highest ranking syllables from CELEX and BAStat in
descending ranking order.
The few overlaps in both ranking sets are printed in bold face. Likely
overlaps between phonological and phonetic syllable forms are underlined.
(The CELEX phonologic coding was mapped to German SAM-PA here and
word initial glottal stops were inserted (e.g. 'und' /Unt/ -> /QUnt/))
| CELEX | di: | de:rg@t@QUntQInb@t@ntsu:dasQaIfErg@nn@d@nde:nQann@nb@rt@rBAStat | ja: | IC | das | n | dan | g@ | tn | @ | da: | di: | t@ | s | d6 | vi:6 | vi: | zi: | @n | b6 | ta:k | n@ |
If we look at the 1000 top ranked syllables (which cover 94.37% of the spoken language in BAStat) in both resources, we find an overlap of merely 47.5%.
Of course this comparison is not entirely valid
since in the case of CELEX the syllabification was done phonologically
with regard to citation word forms while in BAStat the syllabification
is based on the phonetic transcript (which may contain errors). For instance a
syllabic nasal /n/ is is very highly ranked in the syllable ranking of
BAStat but does not even appear in the CELEX syllable type list.
Nevertheless, these examples show that it is not plain sailing to use
phone or syllable statistics from a lexically based resource in experimental
setups dealing with spoken language.
All rights stay with BAS, Ludwig-Maximilians-Universität München.