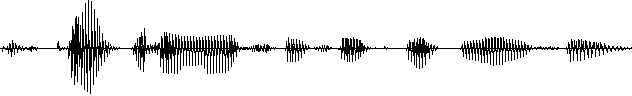Die zentrale Frage der Akustischen Phonetik - die wir bereits ganz zu Beginn formuliert haben - war jedoch auf das Funktionieren der akustischen Informationsübertragung der menschlichen Sprache gerichtet.
Damit wir diesen zentralen Aspekt nicht aus den Augen verlieren, soll in diesem abschließenden, sehr viel kürzeren Abschnitt auf die Aspekte eingegangen werden, die es dem Sprecher und Hörer erlauben, Information mit Hilfe des Sprachsignals zu übermitteln.
Die Ausdrücke mein Geld, dein Geld, kein Geld
unterscheiden sich akustisch nur im vorderen Teil des ersten Wortes.
Trotzdem sind nach der Dekodierung beim Hörer drei semantisch völlig
verschiedene, eindeutige Bedeutungen empfangen worden.
Wir haben gesehen, wie Sprachlaute geformt, und z.T. auch, wie sie gebildet
werden. Wir könnten jetzt mit diesem Wissen eine Kette von
Sprachlauten erzeugen, indem wir diese beliebig aneinanderreihen,
und würden trotzdem nichts verstehen.
Warum ist das so?
Weil wir bisher nur die Dynamik in einem sehr kleinen Kontext
(sog. C Prosodie) behandelt, jedoch den zeitlichen
Ablauf bei der Artikulation von größeren Einheiten (wie Silben oder Wörtern)
vernachlässigt haben.
Die Sprechbewegungen - z.B. die Abfolge von stimmhaft und
stimmlosen Abschnitten - müssen prosodisch wohlartikuliert
sein.
Zu diesen Parametern gehören u.a.
Entfernt man alle Elemente der A Prosodie aus einem Sprachsignal,
entsteht beim Hörer der Eindruck einer Computerstimme,
die nicht mehr als menschliche Rede klassifiziert wird.
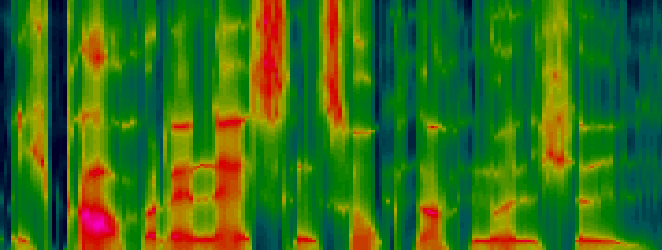
Symbolisch kann man die rhythmische Abfolge von stimmhaften und stimmlosen Bereichen als
'CVCVCVCVC...' darstellen, wobei 'V' einen vokalischen, also stimmhaften Bereich und 'C'
einen konsonantischen, also stimmlosen Bereich markiert.
Mit anderen Worten: wir wissen jetzt, wie der zeitliche Ablauf des
Sprachsignals z.B. innerhalb eines Plosivs aussieht, aber
verständliche oder wohlartikulierte Sprache entsteht
erst, wenn auch der zeitliche Ablauf in größeren Maßstab
so ist, wie wir es bei menschlicher Sprache erwarten.
Nach Tillmann (1980) unterscheiden wir dabei drei verschiedene Arten
der Dynamik im Sprachsignal: die A-, B- und C-Prosodie.
Die mit Hilfe dieser drei Parameter erzeugte Struktur der Äußerung
nennen wir A Prosodie (Tillmann(1980)).
Die A Prosodie kann von Sprecher mehr oder weniger willkürlich
gesteuert werden.
(Aus Haskins Labs Pattern Playback)
Diese Modulation der A Prosodie wird gemeinhin Silbenfolge oder
Silbenrhythmus genannt und stellt die B Prosodie dar.