The Munich
Automatic Segmentation
System MAUS
- Contact: Florian
Schiel
What is
meant by SEGMENTATION?
The aim of phonetic sciences is to analyze the correlation between linguistic
categories (e.g. word, syllable, phone) and corresponding
signals (e.g. acoustic signal, spectrum, articulatory
signal, neuronal signals). Usually, a concrete mapping of
categories to the corresponding sections in the signal is
done according to the aim of the analysis in question. This
results in a partition of the signal in segments, known as
segmentation (and labeling).
Because of the subjective nature of the analysis in question
(dependency on the observer and the thesis and therefore the
necessity of a different description) segmentations are
produced manually according to the relevant aspects of the
analysis. These data are carefully produced and of the
highest possible reliability, which is an absolute prerequisite
for experimental phonetic work.
A good training and a good experience is needed to produce careful and
reliable manual segmentations which are extremely time
consuming (real-time factor up to 400). Therefore, high quality segmentations can usually only be
produced for a small amount of data.
In computational linguistics and digital speech processing, especially in ASR, a large amount of
segmented data is needed. To produce manual segmentations
for this is uneconomical. Therefore, automatic procedures
are developed to automatically segment a large amount of
data in a relatively short time. On the one hand, this is only possible in
reducing the quality of segmentations, which can be traced
back to the impreciseness of the analysis of the acoustic
signal, on the other hand it can be traced back to a
missing hypothesis space of the possible pronunciatiosn of a language.
With MAUS large amount of segmented material can be offered for
research and development in the area of technical speech
processing while consideration of phonetic
information about pronunciation variation. Retrospectively, success in the field of speech
processing lead to significant improvements of automatic segmentation.
Short
Description of BALLOON and MAUS
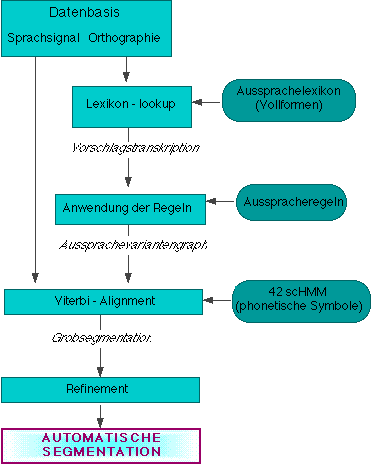 Input-->>>>>
speech signal and related orthographic representation
Input-->>>>>
speech signal and related orthographic representation
Output-->>>>
automatically produced segmentation and labeling on the phonemic level
Video: Introduction to MAUS
Technical implementation:
- hybrid approach consisting of statistical classification of the signal
(HMM) and probabilistic rule based components (statistically derived from a corpus)
- possible pronunciation variants are taken into account
- applicable to read speech as well as to spontaneous speech
Processing steps:
- TEXT NORMALIZATION (BALLOON):
input text are stripped of punctuations, numerals are translated into their full form (e.g. '5.' -> 'fifth'),
dates, time of day, abbreviations etc. are expanded. The final word chain is tokenized.
- TEXT-TO-PHONEME CONVERSIONi (BALLOON):
a phonetic standard transcription is related to the given
orthography using a grapheme-to-phoneme algorithm and an exception dictionary.
- GENERATION OF PRONUNCIATION VARIANTS (MAUS):
the set of probabilistic (or phonologic) pronunciation rules
are applied on the standard transcription of the input
utterance yielding a directed acycylic graph. This graph represents
a multitude of a-priori statistically weighted hypothetical pronunciation variants of the utterance
- VITERBI-ALIGNMENT (HTK):
the
incoming speech signal is time-aligned (HTK) to the most probable path (in combination with the acoustic probabilites) using a set
of continuous HMMs that correspond to the SAMPA symbols of the processed language. The result is a segmentation and labeling
of the utterance.
Download
of MAUS
The MAUS download package comprise a number of scripts and binaries to be
run under Linux. It is possible to run it under WinXX using cygwin (not
contained in the package).
The main scripts of the package are:
- maus : segmentation and labelling (S&L) of a single signal file
- maus.corpus : S&L of a corpus of signal files
- maus.iter : iterative MAUS to adapt the HMM to a new data set
- maus.wrapper : CSH wrapper to call REST webservice runMAUS
- maus.trn : batch-process long chunk-segmentated recordings
and other tools to convert and display S&Ls.
For legal reasons the software package only contains parameter files for German
language support. Please refer to the possibility to call webservices or use the
MAUS Web API (see below) to use other languages than German.
Other software packages needed:
- BALLOON : the grapheme-to-phoneme package of Uwe Reichel
- awk : e.g. GNU 'gawk'
- HTK : http://htk.eng.cam.ac.uk/
- a suitable GNU C compiler to compile the binaries of MAUS
Download
MAUS Webservices
Instead of installing the MAUS package locally on your
computer you can use the MAUS webservices instead.
The input files will be uploaded to the BAS CLARIN server, processed by MAUS
and the result returned to your local computer.
Advantages are:
- no need to compile binaries on your local computer (which often is a nuisance)
- full language support
- always the latest version of MAUS
- batch processing by issueing MAUS webservice calls out of your favourite
script language
A full description of the different webservice calls and their parameters can found in the corresponding
CMDI file. Examples of webservice
calls can be retrieved by the following curl command:
curl -X GET http://clarin.phonetik.uni-muenchen.de/BASWebServices/services/help
A very easy way to utilize the MAUS webservice is to use the CSH wrapper
maus.web which simulates the original MAUS script maus but
internally calls the webservice, thus no requirement for a local installation; you just need a CSH on your computer.
WebMAUS -- a comfortable web-interface
An even easier way than the usage of webservices is the new web-interface WebMAUS:
https://clarin.phonetik.uni-muenchen.de/BASWebServices/index.html
This web application is structured in three parts:
- WebMAUS Basic : label and segment a signal based on its orthographic text
All required processing steps as indicated above are performed automatically. This is very
comfortable, but you have not much control about the process. For instance you cannot influence the
canonical pronunciation form that WebMAUS is using.
- WebMAUS General : this application replicates the complete MAUS script maus.
You have full control of all options, but the input has to be already text-normalized, tokenized and translated into a canonical
pronunciation form.
- WebMAUS MINNI : our newest member of the MAUS family segments and labels speech signals WITHOUT any
text/phonological input, thus only a signal file as input is required.
Publications on
MAUS
Conference papers:
- M.-B. Wesenick, F. Schiel (1994): Applying
Speech Verification to a Large Data Base of German to Obtain a
Statistical Survey About Rules of Pronunciation, Proceedings
of ICSLP 1994, pp. 279 - 282, Yokohama.
- A. Kipp, M.-B. Wesenick, F. Schiel (1996): Automatic
Detection and Segmentation of Pronunciation Variants in German
Speech Corpora; in: Proceedings of the ICSLP 1996.
Philadelphia, pp. 106-109, Oct 1996.
- M.-B. Wesenick, A. Kipp (1996): Estimating
the Quality of Phonetic Transcriptions and Segmentations of Speech
Signals; in: Proceedings of the ICSLP 1996. Philadelphia,
pp. 129-132, Oct 1996.
- M.-B. Wesenick (1996): Automatic
Generation of German Pronunciation Variants; in: Proceedings
of the ICSLP 1996. Philadelphia, pp. 125-128, Oct 1996.
- Kipp, A., Wesenick, B. & Schiel, F. (1997): Pronunciation
Modeling Applied to Automatic Segmentation of Spontaneous Speech;
in: Proceedings of the EUROSPEECH 1997, Rhodos, Greece, pp.
1023-1026.
- F. Schiel (1997): Probabilistic analysis of pronunciation
with MAUS; in: The ELRA Newsletter, December 1997, pp. 6-9.
- Beringer, N., Schiel, F., Brietzmann, P. (1998): German
Regional Variants - A Problem for Automatic Speech Recognition?;
in: Proceedings of the ICSLP 1998. Sydney, Vol. 2, pp. 85ff, Dec.
1998.
- Schiel F (1999): Automatic
Phonetic Transcription of Non-Prompted Speech, Proc. of the
ICPhS 1999. San Francisco, August 1999. pp. 607-610.
- Beringer, N.; Schiel, F. (1999) Independent
Automatic Segmentation of Speech by Pronunciation Modeling.
Proc. of the ICPhS 1999. San Francisco. August 1999. pp. 1653-1656
- Beringer N, Schiel F (2000): The Quality of Multilingual Automatic Segmentation Using German MAUS. Proc. of the International Conference on Spoken Language Processing, Beijing, China.
- N. Beringer (2003): Regeladaptive kategoriale Analyse von
Spontansprache - eine sprachenübergreifende Untersuchung.
DAGA03 - 29. Jahrestagung für Akustik, Aachen.
- Schiel, F. (2004): MAUS Goes Iterative. Proc. of the IV.
International Conference on Language Resources and Evaluation,
Lisbon, Portugal, pp. 1015-1018.
- Kisler T, Schiel F, Sloetjes H (2012): Signal processing via web services: the use case WebMAUS. In: Proceedings Digital Humanities 2012, Hamburg, Germany (pp. 30-34).
- Schiel F, Stevens M, Reichel U D, Cutugno F (2013): Machine Learning of Probabilistic Phonological Pronunciation Rules from the Italian CLIPS Corpus.. In: Proc. of the Interspeech 2013, Lyon, France, 1414-1418.
- Strunk J, Schiel F, Seifart F (2014): Untrained Forced Alignment of Transcriptions and Audio for Language Documentation Corpora using WebMAUS. In: Proceedings of the Nineth International Conference on Language Resources and Evaluation (LREC'14), Editors: Calzolari N, Choukri Kh, Declerck Th, Doğan M U, Maegaard B, Mariani J, Odijk J and Piperidis St, European Language Resources Association (ELRA):Paris, France, isbn: 978-2-9517408-8-4.
- Schiel F (2015): A statistical model for predicting pronunciation.. In: Proc. of the International Conference on Phonetic Sciences, Glasgow, United Kingdom, paper 195.
- Poerner N, Schiel F (2016): An automatic chunk segmentation tool for long transcribed speech recordings, 12. Tagung Phonetik und Phonologie im deutschsprachigen Raum (2016), Munich, Germany, pp. 145-147.
- Kisler T, Reichel U D, Schiel F (2017): Multilingual processing of speech via web services, Computer Speech & Language, Volume 45, September 2017, pages 326-347.
Verbmobil Memos (German):
Dissertations (German):
Kipp, A. : Automatische Segmentierung und Etikettierung von
Spontansprache; Shaker Verlag Aachen 1999.
Beringer, N. : Regeladaptive kategoriale Analyse von Spontansprache; Shaker Aachen 2002