![[*]](footnote.gif)
| Up | Info about the project | Table of Contents of this CD | System Requirements and Installation | Copyright | Disclaimer | Contact |
Dafydd Gibbon and Harald Lüngen
Universität Bielefeld, Germany
This article is part of the documentation in Wahlster 2000
The Verbmobil system is able to process a vocabulary of 10157 German words
(full word forms) in the appointment scheduling and travel planning scenario.
This is quite a high number compared with current systems with a similar task.
Still, the number is very low in view of the number of the actual
(lexicalised) and potential (creatable) German words and only makes sense on
the assumption that Verbmobil is to be used in the limited domains of
appointment scheduling and travel planning. Generally, the ratio between
full words form types and stem (lemma) types in German texts is between 3:1
and 5:1, due to inflectional variation depending on the text type. English,
in contrast, has a word form variation factor of only slightly![]() 1.
German also has a high proportion of word formations (derivatives and
compounds) in the vocabulary. These complex words are consistently
transcribed as single words in transcriptions of speech, whereas in English
transcriptions they are very frequently already orthographically segmented by
blanks or hyphens, cf. einundzwanzig vs. twenty-one,
Reisebüro vs. travel agency, and auszudrucken vs.
to print out. Moreover, a larger percentage of the
out-of-vocabulary items encountered by the system in test runs are
compounds and derivatives, and inflectional forms with stems that are already
included in the vocabulary. It is well-known that this percentage increases
with increasing vocabulary.
1.
German also has a high proportion of word formations (derivatives and
compounds) in the vocabulary. These complex words are consistently
transcribed as single words in transcriptions of speech, whereas in English
transcriptions they are very frequently already orthographically segmented by
blanks or hyphens, cf. einundzwanzig vs. twenty-one,
Reisebüro vs. travel agency, and auszudrucken vs.
to print out. Moreover, a larger percentage of the
out-of-vocabulary items encountered by the system in test runs are
compounds and derivatives, and inflectional forms with stems that are already
included in the vocabulary. It is well-known that this percentage increases
with increasing vocabulary.
One way to cope with this is to rely on word compositionality, by analogy with the sentence compositionality used to recognise sentences. In addition to decomposing words into phonological units such as syllables or phonemes for actual decoding purposes, further decomposition into morphemes, which have a semantic basis, suggests a way forward for handling languages like German with rich inflectional morphology. Morphological decomposition enhances the interface between speech components and language components both in off-line lexical resource acquisition and (though this is a long-term perspective) in speech recognition architectures. The question of how to include which kind of morphological knowledge in the speech recognition process to gain the best results is still an object of basic research. Unlike syllables, phonemes etc. morphemes require semantic definition criteria, indicating that their main role may be in enhanced language models rather than decoders. Some experimental speech recognition systems which examine aspects of applying morphological knowledge on-line have been implemented and evaluated within Verbmobil-internal research projects or Verbmobil spin-off projects, see [Geutner1995], [Berton et al.1996], [Lüngen et al.1996], [althoff1997], [Strom and Heine1999], and [Pampel1999].
A lexicon which provides more elaborate information than simple pronunciation tables needs to include morphotactic, morphographemic, and morphophonological properties of word forms and to store them efficiently in a redundancy-free knowledge base in order to avoid inconsistencies. In computational linguistics, inheritance-based lexicon frameworks have been used in numerous speech and language applications, as well as in theoretical developments, over the past decade and a half, e.g. the HPSG lexicon (pollard87, flickinger87, and koenig99), or ILEX (gibbon91c). Inheritance lexica were first used for generating speech processing resources in the SUNDIAL project (andry92).
| Top of this page |
An inheritance-based lexicon for speech processing was developed by the Bielefeld lexicon group during Verbmobil Phase I (1993-1996), see [Bleiching1995], and [Bleiching et al.1996], and has been further developed in Verbmobil-Phase-II (luengen98c). A dual lexicon architecture was adopted: (1) a background lexicon as a general resource, (2) task-specific daughter lexica generated with complex filters. The actual project deliverable, however, is the lexical database, defined as one specific compiled-out daughter lexicon in which a wide range of lexical information types provided by other Verbmobil Partners, i.e. sources external to the background lexicon, are integrated.
| Top of this page |
The model for the background lexicon is sign-based, and the basic objects contained in it are lexical signs, i.e. objects associated with attributes denoting compositional and interpretative lexical properties. A second kind of lexical object is the lexical type which denotes a class of signs. The lexical signs which form the base entries of the background lexicon are of the type abstract-lemma. An abstract morphological lemma represents information common to all elements of one inflectional paradigm. There are five subtypes of abstract-lemma: noun-lemma, verb-lemma, adjective-lemma, detpro-lemma, and nonflex-lemma, reflecting different paradigm class types.
Lexical types which generalise over lemmata are organised into two hierarchies:
The lexicon was originally implemented in DATR, and after the introduction of the syncretism relation was re-implemented in Prolog for reasons of efficiency, compatibility and flexible querying. The main application of this lexicon is to provide input to a paradigm generator, also implemented in Prolog, which operationalises the syncretism-based paradigm mapping and assigns the abstract lemmata of the knowledge base their orthographic and phonemic surface forms. The generator has full coverage of German inflectional morphology, not just for forms attested in the Verbmobil corpora. The final lexicon includes 11398 lemmata (derived from all the word forms found in the Verbmobil corpora) which are projected onto 75607 word forms; resolution of syncretism results in 512068 morphosyntactic mappings to word forms.
| Top of this page |
A further component of the hierarchical background lexicon is a morpheme lexicon. Here, the morphemes of German, in the form of their morphologically and lexically conditioned allomorphs, are specified for those features that are refered to in the morphotactics. The morpheme lexicon contains value specifications of 5700 morphs, including 405 different combinatorial readings of derivational affixes, and about 3600 lexical roots (lexical roots found in the Verbmobil corpora by the morphological segmentation procedure). The inflectional suffix entries are generated from the paradigm and syncretism hierarchy knowledge base described above. Entries for function words (which generally do not participate in German word formation) are generated from the background lemma lexicon described above. They are specified for 38 combinatorial morphophonological features (right- and leftboundness, root-adjacency, potential stress), morphotactic features (e.g. nativeness, interfixes and linking morphemes, umlauting and umlaut-causing properties, inflectional class), and morphosyntactic features. The morphological features and their value domains are explicated as the appropriate attributes for a set of mutually exclusive lexical base types (luengen00b).
| Top of this page |
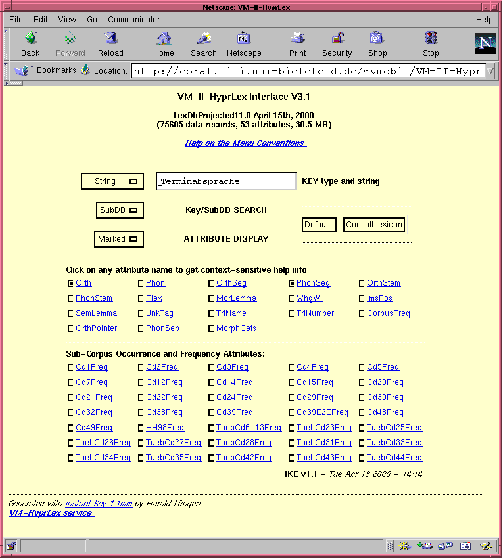
The Bielefeld Lexicon Database which is generated from the morphologically structured background lexicon is formatted as a relational database with hierarchically structured fields. The relational database is implemented, for portability, as a classical UNIX database in the form of a large ASCII table. The record delimiter is UNIX newline, and the field delimiter is space, the field-internal separators are semicolon for disjunctive vector components and comma for conjunctive vector components. The database is distributed to partners as a database table file, which also forms the core of an CGI-based interactive WWW database with online context sensitive help, HYPRLEX (Figure 1). The HTML query interface form is automatically generated by IKE, a generic form generator developed in Verbmobil Phase I.
The first field of a record in the database is defined to be the unique
record key.
A unique record key is a fully inflected word form in Verbmobil orthography
according to [Burger1997], identical to the word form tokens that are found
in the Verbmobil dialog transliterations and Partitur files (Chapter
![[*]](crossref.gif) ).
All homographic relations, whether based on syncretism or
homonymy, are represented as equal-length vectors of possibly redundant
disjunctive values in the remaining fields;
the vectors essentially represent distributed disjunctions
as introduced by [Krieger and Nerbonne1992].
Attribute values may be either atomic, or conjunctive vectors,
i.e. vectors whose components are to be interpreted as conjunctions of values.
The components of disjunctive vectors may be either conjunctive vectors,
or atomic. Components of conjunctive vectors are only atomic.
).
All homographic relations, whether based on syncretism or
homonymy, are represented as equal-length vectors of possibly redundant
disjunctive values in the remaining fields;
the vectors essentially represent distributed disjunctions
as introduced by [Krieger and Nerbonne1992].
Attribute values may be either atomic, or conjunctive vectors,
i.e. vectors whose components are to be interpreted as conjunctions of values.
The components of disjunctive vectors may be either conjunctive vectors,
or atomic. Components of conjunctive vectors are only atomic.
The intensional coverage (types of lexical information) includes: morphological boundaries, morpheme type sequences, canonical phonological transcription (in SAMPA notation), syllable boundaries, lexical stress, morphological lemma, orthographic stem, phonological stem, morphosyntactic categories, proper name type:
Entry 10788 matches String key verkehrsg"unstiger:
Orth: verkehrsg"unstiger
Phon: f6ke:6sgYnstIg6
f6ke:6sgYnstIg6
OrthSeg: ver+kehr#+s#g"unst+ig#+er
ver+kehr#+s#g"unst+ig+er
PhonSeg: f6.+k'e:6#+s#g''Yns.t+I.g#+6
f6.+k'e:6#+s#g''Yns.t+I.g+6
OrthStem: ver+kehr#+s#g"unst+ig
ver+kehr#+s#g"unst+ig+er
PhonStem: f6.+k'e:6#+s#g''Yns.t+Ig
f6.+k'e:6#+s#g''Yns.t+I.g+@r
Flex: A,mixed,sg,nom,mask,pos
A,strong,pl,gen,fem,pos
A,strong,pl,gen,mask,pos
A,strong,pl,gen,neut,pos
A,strong,sg,dat,fem,pos
A,strong,sg,gen,fem,pos
A,strong,sg,nom,mask,pos
A,unflekt,komp
MorLemma: verkehrsg"unstig
verkehrsg"unstiger
WhgWl: 1
ImsPos: ADJD
SemLemma: verkehrsg"unstig
UnkTag: *nil*
TrlName: 0
TrlNumber: 0
CorpusFreq: 1
OrthPointer: *nil*
PhonSep: f-6-k-e:6-s-g-Y-n-s-t-I-g-6
f-6-k-e:6-s-g-Y-n-s-t-I-g-6
Attribute definitions:
).
| # | compound boundary |
| + | derivational or enclitic boundary |
| #+ | inflectional boundary |
| compound boundary (instead of # when |
| # | compound boundary (# implies a syllable boundary except in a highly lexicalised sequence |
| .C# where C is a consonantal phoneme (einander: ?aI.n#'an.d6) | |
| + | derivational or enclitic boundary |
| #+ | inflectional boundary |
| ' | (preceding a vowel) primary stress |
| '' | (preceding a vowel) secondary or tertiary stress |
| . | syllable boundary (when not collapsing with #). |
| Top of this page |
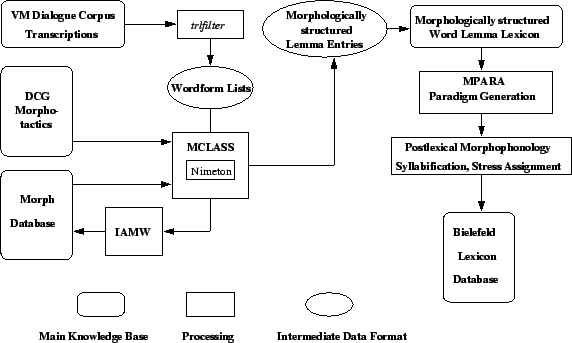
The task of lexical acquisition is to derive fully-fledged entries for the background lexicon in the format described above from the Verbmobil Corpora. Preprocessing (consistency check, format adaptation, tokenisation) is performed with the TRLFILTER, developed in Bielefeld in Verbmobil-Phase-I and re-implemented and modified in Munich in Phase II (gibbon95f). The words attested in the Verbmobil corpora are lemmatised , and grapheme-phoneme conversion is applied; these tasks are performed by the Bielefeld Prolog-Parser MCLASS, which contains the following components:
The architecture of the acquisition process with its various components is illustrated in Figure 2.
The parser was evaluated by automatic formal verification of the data types, by automatic alignment of output samples with manually verified test suites and by operational tests and coordination agreements with Verbmobil partners.
| Top of this page |
A further research area included decision-tree driven automatisation of the interactive acquisition of feature vectors for the morpheme database. Knowledge about appropriateness specifications for all fields of a database record (corresponding to explicit feature structure types) is encoded in a decision tree. The attributes represented in the decision tree are interpreted by the acquisition program IAMW and control subsequent interactions with the lexicographer. When the value of an attribute cannot be inferred from feature co-occurrence restrictions and feature specification defaults, the lexicographer is requested to provide the correct value from a set of possible values.
IAMW is a generic tool that expects a decision tree in a declarative Prolog-specific format which permits databases with the structure described in section (2.2) to be acquired. The decision trees may be specified by linguists, or may be machine-learned from training data as described in [Lüngen and Sporleder1999].
| Top of this page |
One of the tasks of the Bielefeld lexicon group was to co-ordinate multilingual wordlists and define the lexical coverage of the Verbmobil system, specified as a vocabulary of 10000 word forms for German, 6000 for English (which roughly corresponds to 10000 in German in terms of corpus word form tokens), and 2500 for Japanese. The final wordlists for Verbmobil System 1.0 contain 10157 German, 6871 English, and 2566 Japanese word forms. The system can actually process a larger vocabulary, as the recognizer dictionaries include additional proper name lexica for a class-based treatment in the language modules (schaaf98).
A wordlist is the data structure that defines the coverage of a module lexicon. For the generation of wordlists, criteria ensuring domain-specific intensional coverage, corpus consistency and translation equivalence between monolingual wordlists were developed by the Bielefeld lexicon group. A significant logistic problem was that the term word is used in different senses when talking about the various module lexica such as the speech recogniser dictionary, or a syntax-semantics lexicon:
The term lemma, in turn, may appear in other contexts,
too:
Within Verbmobil, wordlists are defined on the basis of actual word forms attested in the corpora, because these are the linguistic units employed in current word recognition systems. They also appear at the interface to the language modules, the word hypotheses graph (WHG). Thus, a wordlist also defines permissible arc labels in a WHG.
| Top of this page |
Extensional Coverage Criteria define the selection of lexical entries (forms, lemmata, or records) to be included in the module lexica.
An operational definition of word form, as used in the Verbmobil project, is provided in terms of the procedure described in [Gibbon and Steinbrecher1995] for extracting a word form list automatically from a transcribed corpus. But for several reasons it is not desirable simply to define all attested words as lexical since words with a very low token frequency may turn out to be (1) transcription errors (such as micht), (2) ad-hoc word formations (such as Diaabend-Weintrink-Revisionstreffen), or (3) words totally deviating from the given scenario and domain (Safaribüchse). None of these should be stored in the module lexica because of the vanishingly low probability of re-occurrence. Only attested words which appear more than N times are included, whereby the largest N which permits 10000 to be reached is selected.
| Top of this page |
Intensional coverage criteria define the types of lexical information to be associated with lexical entries, represented as features, values of attributes, or fields. They are independent of the corpus but, like the corpus, depend on the given scenario and system requirements. They may be applied to increase extensional coverage if it cannot be guaranteed that all the words that are known to be needed in the application actually occur in the corpus (as is indeed the case). The following intensional coverage criteria are used to define additional extensional coverage in the Verbmobil domain:
CzerczinskyUNK_Surname
Parkhotel
Kröpcke
| Top of this page |
Multilinguality in the Verbmobil context requires that the monolingual word
list WL
![]() for language L
for language L
![]() must contain all the words that are needed to translate the words in the
monolingual wordlist for language L
must contain all the words that are needed to translate the words in the
monolingual wordlist for language L
![]() . This means
that in addition to the words obtained from the
L
. This means
that in addition to the words obtained from the
L
![]() -corpora,
the list WL
-corpora,
the list WL
![]() must also contain the translation equivalents of
WL
must also contain the translation equivalents of
WL
![]() .
Of course, translation equivalents for a word cannot simply be given out
of the blue, as each possible translation is context-dependent.
The task is feasible, though, for a restricted domain like the Verbmobil
domain.
Since the wordlists are corpus-based, the contexts in which each word of
WL
.
Of course, translation equivalents for a word cannot simply be given out
of the blue, as each possible translation is context-dependent.
The task is feasible, though, for a restricted domain like the Verbmobil
domain.
Since the wordlists are corpus-based, the contexts in which each word of
WL
![]() occured are known and thus exact translations
can be given.
There are in fact two sources from which translations can be obtained:
(1) transfer rules (cf. Chapter ),
(2) aligned translations of the data produced by human translators
or automatic translation (cf. Chapter ).
occured are known and thus exact translations
can be given.
There are in fact two sources from which translations can be obtained:
(1) transfer rules (cf. Chapter ),
(2) aligned translations of the data produced by human translators
or automatic translation (cf. Chapter ).
We can thus define the translationally equivalent wordlist:
The translation equivalent of a given wordlistNote that the translation equivalent is defined here for a corpus-derived wordlist, not for single words, permitting context-dependent definition for words. But at the same time this makes the above definition not exactly operationalisable for Verbmobil, since the extraction of WL from C is not performed exactly dialog-wise or dialog-turn-wise, but is rather frequency-based, and to some degree intensionally defined, as specified above. Therefore, we describe a transfer-rule-based and operationalisable approach, which is an approximation of the above given definition:extracted from a dialog corpus C is the list of words of the target language that are needed for the translation of C.
The translation equivalent of a wordlist WL, which was extracted from a dialog corpus C, is the list of lemmata that occur on the right hand side of a transfer rule T, whose left hand side contains a semantic lemma with a morphologically corresponding entry in WL.
The German wordlist vmII-whg.wl.5.1 was generated from the
Verbmobil transliterations of spoken dialogs available at
the beginning of 2000. This list (containing 10568 word forms) was filtered
and extended according to the criteria defined above.
The processor was implemented as a large UNIX shell script.
The final version contains 10157 word form types, 8438 of which are found
in the dialog corpora.
The English and Japanese final wordlists have been generated accordingly at
the CSLI (cf. Chapter ) and the DFKI (Chapter ).
| Top of this page |
The tasks faced by the Bielefeld lexicon group at the start of the Verbmobil project were partly linguistic and phonetic, partly technological, and partly problems of multi-disciplinary communication. The lexicographic integration task required the development of exact coordination procedures, formally fully specified interfaces, interface verification tools, corpus processing and validation tools, acquisition tools, including machine learning components, lexical database management and access tools, and an interactive website.
Perhaps the main achievements of the Bielefeld lexicon group are (1) the development of a formally fully specified, empirically complete, and fully operational inheritance-based description of German morphology and morphophonology, which is also the first of its kind and has been widely acknowledged in the literature; (2) the establishment of standards for spoken langauge lexicography, which have entered into European language engineering standardisation intitiatives (cf. GibbonMooreWinski1997). All of these results are available for use in future work by the international speech and language community.
| Top of this page |
| Top of this page |
Mail to ![]()